dplyr: data wrangling
extension topic
Dr. Elijah Meyer
NC State University
ST 511 - Fall 2025
2025-11-24
Checklist
– HW 6 released (due November 30th at 11:59pm)
– Don’t forget about the statistics experience
– Final Exam is Dec 8th at 3:30
– Please clone today’s dplyr AE
Practice problems
– I’ll either make something
– Or write a guide
Data wrangling
Why is data wrangling important?
Data wrangling
From the reading:
Often you’ll need to create some new variables or summaries to answer your questions with your data, or maybe you just want to rename the variables or reorder the observations to make the data a little easier to work with.
dplyr package
The dplyr package in R is a collection of functions that help users manipulate data frames. It’s a core part of the tidyverse, a group of packages in R
– filter()
– mutate()
– count()
– and more!
Joins Summary
– There are many ways to join data
– Let the join criteria choose the function for you
– Data sets are joined by a “key”
– The key(s) default to common names across data sets unless specified
– Can join on variables with different names by using the = sign by = c("variable1" = "variable2")
Tidy Data
There are three interrelated rules that make a dataset tidy:
Each variable is a column; each column is a variable.
Each observation is row; each row is an observation.
Each value is a cell; each cell is a single value.
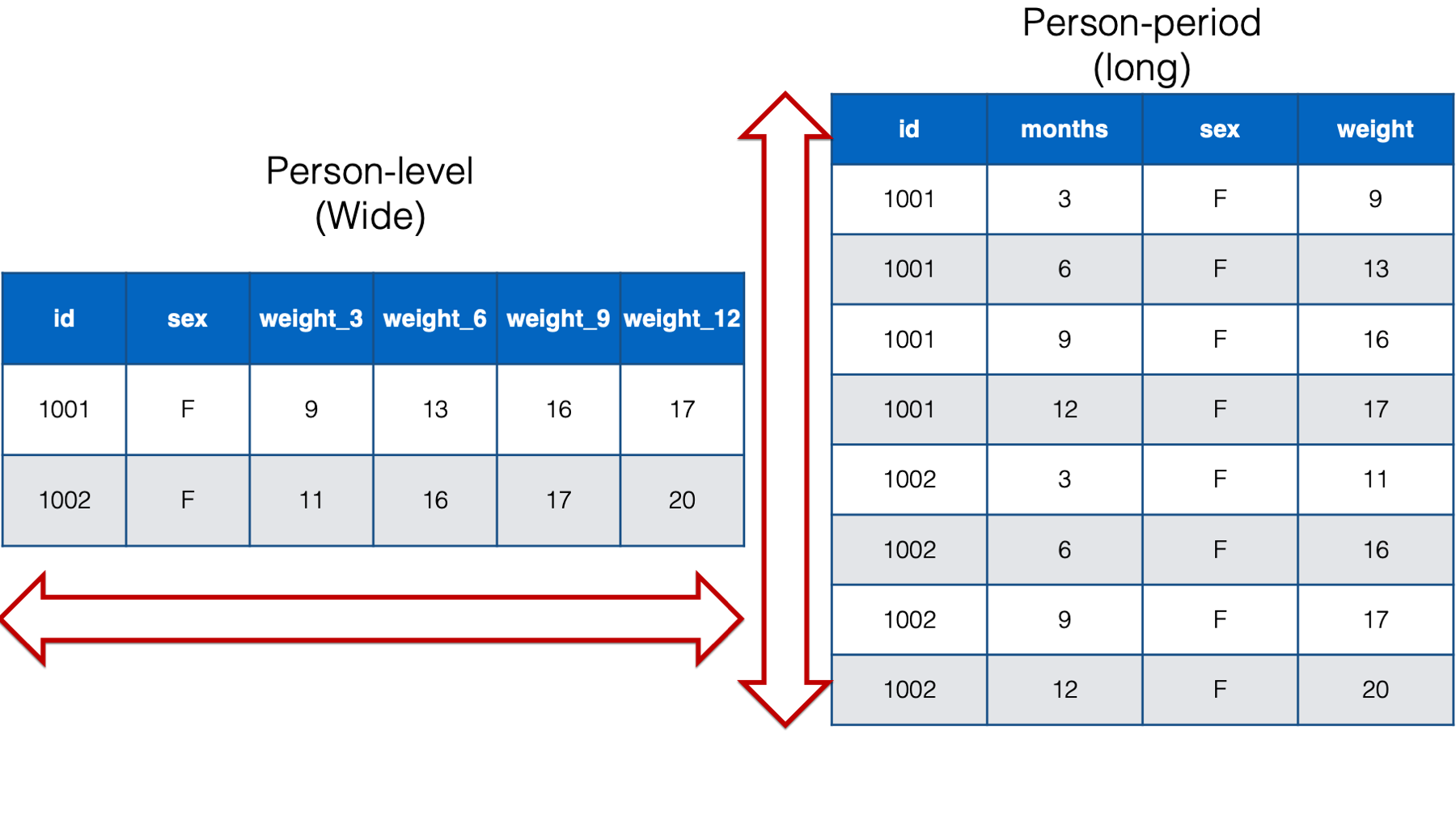
Motivation
– Sometimes, data are not in this format…
pivots
– pivot_longer
– pivot_wider
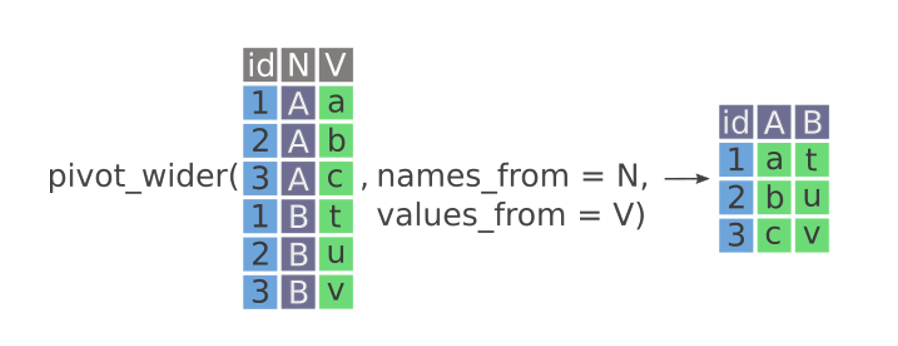
pivot_wider
– Making tables for quick comparison / display purposes
– names_from
– values_from